
Sales tools love to promise a never-ending stream of leads with a single click. What they don't tell you is that lead scraping comes with some serious hidden baggage. The uncomfortable truth is that a huge chunk of scraped data is junk, the methods themselves can land you in hot water, and the whole process is often frustratingly unreliable.
The Hidden Costs of Automated Lead Scraping
Sales and recruiting pros are sold a dream: unlimited leads, automated prospecting, and a pipeline that’s always full. Lead scraping tools are pitched as the magic wand for making it happen, promising to pull valuable contact info from websites with almost zero effort. But this glossy picture conveniently leaves out the common challenges that can torpedo your outreach before you even send the first email.
Think of traditional lead scraping like casting a giant fishing net with huge holes. Sure, you’ll haul in a massive catch, but a huge portion of it will be irrelevant, outdated, or incomplete. This is where the frustrating and costly problems begin—the ones sales tools rarely mention in their marketing copy.
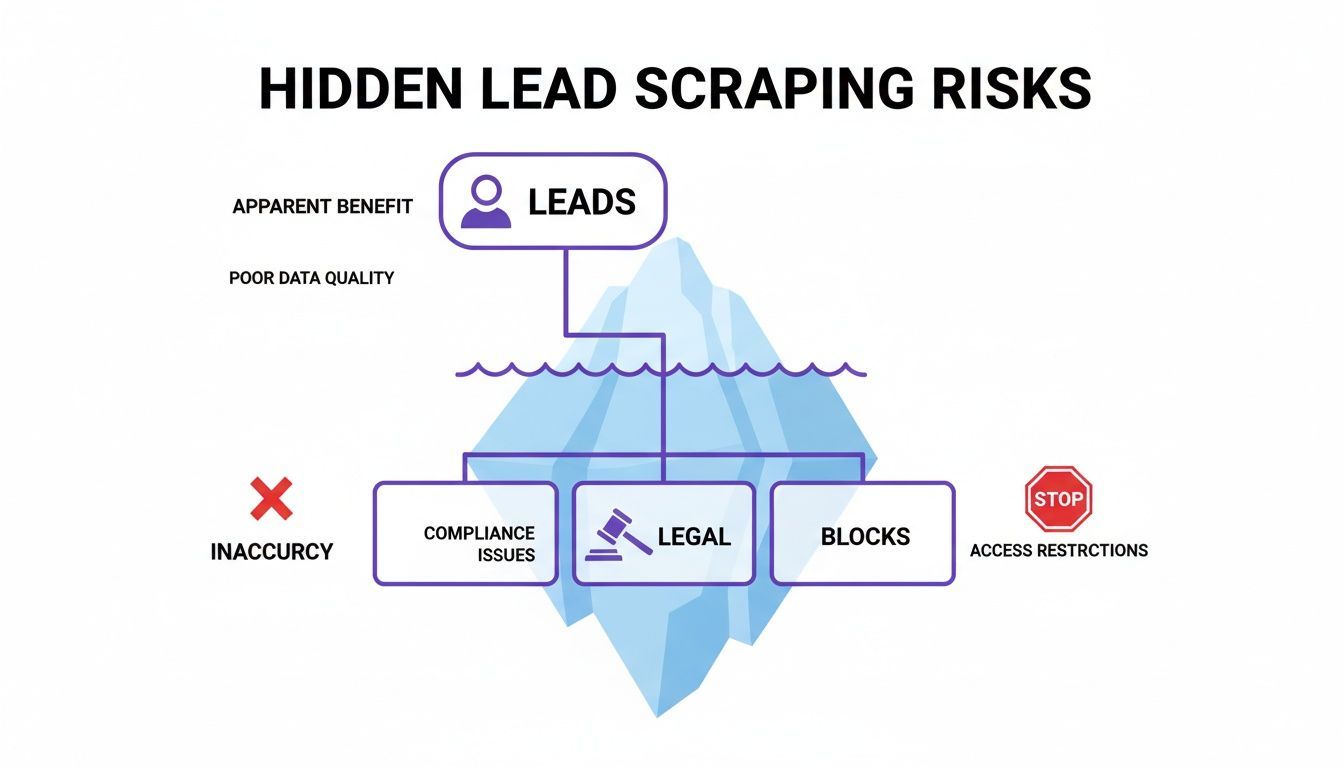
The Iceberg of Lead Scraping Risks
That initial, easy win of grabbing names and company titles? That's just the tip of the iceberg. Lurking just beneath the surface are some substantial risks that can sink your entire sales operation.
- Wasted Outreach Efforts: A shockingly high percentage of scraped data is just plain wrong. Reaching out to outdated profiles or using incorrect information doesn’t just waste your time; it actively damages your brand’s credibility.
- Compliance and Legal Dangers: Scraping can easily violate a website's Terms of Service and might put you at odds with data privacy laws like GDPR. The consequences can be anything from getting banned from a platform to facing steep legal fines.
- Technical Roadblocks: Websites are in a constant battle against scrapers. The tool that works perfectly today could be completely blocked tomorrow, leaving you with an unreliable lead source and a broken workflow.
The old "scrape-and-blast" playbook is losing its edge because it completely ignores these fundamental issues. It’s a strategy built on quantity over the quality that actually drives conversations and closes deals. As sales cycles get more nuanced, you have to understand the true cost of your lead generation methods. For more on how to structure these costs, check out our guide on creating a pricing model for your lead data business.
This article pulls back the curtain on what sales tools aren't telling you about lead scraping. We'll dive into the data quality catastrophe they ignore, the legal minefield they create, and exactly why your scraped leads often fail to convert. More importantly, we’ll show you a smarter, safer way to build lead lists—one that uses modern, no-code tools like ProfileSpider to put accuracy, privacy, and sustainable growth first, right from the start.
The Data Quality Catastrophe Most Tools Ignore
Sales tools love to sell the dream of a bottomless well of leads, but they conveniently gloss over a critical, pipeline-poisoning detail: the data they deliver is often shockingly bad. This isn't just a minor hiccup; it's a catastrophe waiting to happen, contaminating your entire sales process right from the start.
Most traditional lead scrapers are cloud-based, meaning they send bots to crawl websites from anonymous data centers. Think of their data as unfiltered tap water. It looks like you're getting a ton of it, but it's often contaminated with outdated details, half-finished profiles, and information that's just plain wrong. This problem is especially bad on dynamic platforms like LinkedIn, where people’s careers change in the blink of an eye.
The Rise of Ghost Leads and Inaccurate Data
Websites are in a constant arms race against automated scrapers. They deploy sophisticated defenses designed specifically to feed bots old or jumbled data, which leads to massive error rates. This tactic floods your lead lists with "ghost" profiles—contacts who left the company months ago, have a completely different job title, or whose details are entirely fabricated by the anti-scraping system.
Sales tools will brag about scraping millions of leads effortlessly, but they always skip the part about the brutal data inaccuracy rates that can derail your entire pipeline. A 2023 report from Imperva found that a staggering 10.2% of all global web traffic now comes from scrapers. What these tools don't tell you is how anti-scraping tech inflates error rates—we're talking up to 40-60% invalid leads in bulk scrapes from dynamic sites like LinkedIn, according to benchmarks from ScrapeOps. Learn more about the challenges of web scraping in the 2024 Mordor Intelligence report.
This flood of bad data isn't just an annoyance. It directly translates into wasted time, a damaged brand reputation, and a sales team that’s completely burnt out from chasing shadows. When your data is unreliable, your entire outreach strategy is built on a foundation of sand.
This is the hidden iceberg of lead scraping. The easy lead collection is just the tip, while the massive problems of data inaccuracy, legal exposure, and technical blocks lurk dangerously beneath the surface.
How ProfileSpider Overcomes This Challenge
This is exactly where a modern, no-code tool like ProfileSpider changes the game. It overcomes these challenges by working locally as a Chrome extension, right inside your own browser, instead of deploying clumsy, cloud-based bots that are easily detected and fed garbage data.
This simple shift has three huge advantages for data quality:
- It Looks Human: Because ProfileSpider operates from your authenticated browser session, its activity looks like normal human browsing. This helps it fly under the radar of many common anti-scraping traps.
- It Grabs Real-Time Info: You’re extracting data directly from the live, updated version of the page you're looking at, not some outdated copy stored on a server halfway across the world.
- It's AI-Powered: The tool’s AI is trained to intelligently identify and parse the structure of a profile page, ensuring it grabs the right information for names, titles, companies, and contact details.
To see the difference in action, let's break down how these two approaches stack up.
Cloud-Based Scrapers vs. ProfileSpider
| Feature | Traditional Cloud Scrapers | ProfileSpider (Local, No-Code) |
|---|---|---|
| Data Source | Cached or bot-accessed website versions | Live, real-time page within your browser |
| Detection Risk | High. Easily identified by IP and behavior. | Low. Blends in with normal user activity. |
| Accuracy Rate | Often 40-60% error rate on dynamic sites. | Consistently higher due to real-time data access. |
| Data Freshness | Can be hours or days old. | Instantaneous. What you see is what you get. |
| Privacy | Your account credentials may be stored on their servers. | 100% private. Never accesses or stores your credentials. |
By processing data locally, ProfileSpider achieves a level of accuracy that cloud tools just can't match. It ensures the profiles you collect are real, relevant, and ready for outreach, protecting your business from the crippling cost of bad data.
At the end of the day, low-quality leads are a primary driver of failed outreach, which is a key reason why your lead enrichment is failing. The goal isn't just to gather leads; it's to gather the right leads. And that journey always starts with quality data you can actually trust.
Navigating The Legal and Ethical Minefield
Most sales tools pitch lead scraping as a simple, risk-free way to flood your pipeline. What they don't exactly advertise is the complex legal and ethical tightrope you’ll be walking. Firing up an automated scraper without understanding the rules is a common pitfall that can lead to serious consequences, from getting your social media accounts banned to facing expensive legal threats.
The most common risk, and usually the first one you'll hit, is violating a platform's Terms of Service (ToS). Dig into the fine print of any major social network or professional directory, and you'll find they almost always forbid automated data collection. When your scraping tool starts hammering their servers, you're not just bending the rules—you're waving a giant red flag that can get your account, and maybe even your company's IP address, permanently banned.

Beyond Terms of Service: Data Privacy Laws
The real trouble starts when you step into the world of data privacy regulations like the General Data Protection Regulation (GDPR) in Europe or California’s CCPA. These laws give people specific rights over their personal data, and they don't care if that data was "publicly available."
That old argument—"if it's public, it's fair game"—is a dangerously simplistic way to look at it. What really matters is how you collect, process, and store that information. Just grabbing someone's name, email, and job from a website and dumping it into your marketing list without consent can put you on the wrong side of the law. We're talking about fines that can climb into the millions. To get a real handle on this, it's smart to consult a comprehensive legal guide to web scraping and stay up to date.
While sales tools are busy hyping 'unlimited leads,' they often bury these explosive legal risks in vague disclaimers, leaving users exposed to the lawsuits and platform bans that have spiked since 2020. The ground is constantly shifting here. By 2025, it's expected that 85% of Fortune 500 firms will have strict anti-bot policies locked down. And with the web scraping market on track to nearly double to $2 billion by 2030, you can bet regulatory scrutiny is only going to get tighter.
How ProfileSpider Overcomes This Challenge
This is where the actual design of your sales tool becomes incredibly important. A lot of cloud-based scrapers are built on a shaky legal foundation, pooling data from thousands of users onto their own central servers. This creates a massive, shared database of scraped info, which is a compliance nightmare and cranks up your risk profile.
"The central flaw of most scraping tools is that they take control of the data away from the user. When your leads are stored on a third-party server, you lose oversight of how that data is managed, secured, and processed, creating a significant compliance blind spot."
There's a much safer way forward, and it’s built on a privacy-first design. This is the core principle behind a tool like ProfileSpider. Because it’s a browser extension, it works completely differently by design:
- Local-First Storage: All the data you extract is stored right there in your browser's secure storage (IndexedDB). It never hits our servers, which means you—and only you—are the controller of that information.
- User-Controlled Processing: The data extraction happens on your machine, using your own authenticated session. This lines up perfectly with modern data privacy principles that are all about user control and minimizing data exposure.
By keeping the data entirely on your device, ProfileSpider helps you sidestep the risks that come with cloud-based tools co-mingling everyone's data. It puts you in the driver’s seat, letting you manage your lead lists in a way that respects your own company’s privacy policies and legal obligations. To really get into the weeds, you can read more about whether website scraping is legal in our detailed guide. This approach doesn't make all the risks vanish, but it gives you a much more defensible and transparent framework for generating leads today.
Why Your Scraped Leads Aren't Converting
You did it. You ran a scraper and now you’re sitting on a massive list of potential leads. But when you launch your outreach campaign, you’re met with a wall of silence. Open rates are in the gutter, replies are nonexistent, and the sales pipeline you were hoping to fill is starting to feel awfully empty.
This is a frustratingly common pitfall, and it boils down to a hard truth most sales tools won’t tell you: a scraped lead is not a qualified prospect.
What you get from a basic scraper is often just a name and a company—a raw data point, completely stripped of the context you need to actually build a connection. It’s like being handed a phone book with half the numbers torn out. Without the right information, even the best sales team on the planet is set up to fail from the start.
The Silent Killer of Sales Pipelines: Data Decay
The second you scrape a lead, a countdown timer begins. This is data decay, and it’s happening a lot faster than you think. People are constantly changing jobs, getting promoted, moving to new companies. The contact info that was perfectly accurate last month? It could be totally useless today.
This problem gets even worse with traditional cloud-based scrapers. Many of them work by pulling from cached, outdated versions of web pages, meaning they’re delivering data that’s already stale on arrival. You end up filling your CRM with ghosts, which leads directly to bounced emails, wasted calls, and a demoralized team chasing prospects who aren't even there anymore.
Mind the Enrichment Gap
Beyond simple decay, there’s an even bigger problem: the enrichment gap. A name and a job title are just table stakes. To craft a message that actually lands—something personal and compelling—you need a whole lot more. This is the information that turns a cold name into a warm opportunity.
The enrichment gap is all about those critical missing details:
- Verified Email Addresses: The absolute essential for just reaching the person.
- Direct Phone Numbers: A must-have for any sales team that relies on calls.
- Up-to-Date Social Profiles: Key for understanding their professional background and recent activity.
- Correct Company Information: Crucial for making sure your pitch is actually relevant to what they're doing now.
Many sales tools promise the moon but conveniently gloss over the fact that unverified scraped leads have abysmal conversion rates—sometimes as low as 2-5%. When you stack that against a 21% industry benchmark for qualified leads, the cost of bad data becomes painfully clear. Research from Gartner drives this home, showing that a staggering 68% of scraped leads are missing essential info like a verified email, dooming outreach before it even begins. This gap fuels a massive amount of waste in B2B spending. You can dive deeper into these market dynamics in the 2025 Web Scraping Market Report.
How ProfileSpider Overcomes This Challenge
This is where you need to get smarter about your approach. You don't just need another scraper; you need a tool that actively bridges that enrichment gap and hands you conversion-ready contacts. That’s the entire philosophy behind ProfileSpider. We designed it to be more than a simple data extractor—it’s a personal CRM builder that helps you create high-quality, fully detailed contact lists.
The real value isn’t in how many leads you can scrape. It’s in the quality of the profiles you can build. A single, well-enriched contact is worth a thousand outdated, incomplete ones.
ProfileSpider was built to tackle the enrichment gap head-on. Its AI-powered engine doesn’t just skim the surface.
- AI Profile Detection: It intelligently identifies and pulls structured profile data, making sure you get accurate names, titles, and company details directly from the live page.
- One-Click Contact Enrichment: See a profile that’s missing an email or a social link? Just click "Enrich." ProfileSpider will automatically navigate to that person’s other detail pages (like a personal site or other linked social profiles) to find and add that missing info to your list.
This completely changes the workflow. Instead of exporting a messy CSV of half-baked leads, you're building a clean, organized, and enriched database right inside your browser. You can add tags, make notes, and create custom lists for different campaigns—all before that data ever touches your main CRM. By focusing on quality and giving you the tools to enrich on the spot, ProfileSpider makes sure your leads are primed for conversion, giving your outreach the best possible shot at success.
Overcoming Technical Hurdles Like Blocks and CAPTCHAs
Ever had a lead scraping tool that worked perfectly one day and then completely stopped the next? You’re not alone.
This is the frustrating reality of the cat-and-mouse game between automated scrapers and the websites they target. It’s a technical battleground that most sales tools conveniently forget to mention in their marketing.
Websites are, understandably, protective of their data. To fend off automated bots, they deploy a whole arsenal of anti-scraping technologies. These digital gatekeepers are designed specifically to identify and shut down the robotic activity that most scraping tools rely on, leaving your lead generation efforts dead in the water.
The Digital Defenses You’re Up Against
Understanding these defenses is the first step to getting around them. When your scraper suddenly fails, it’s almost always due to one of these common roadblocks.
- IP Blocking: Most cloud-based scrapers send thousands of requests from a small handful of IP addresses hosted in data centers. Websites can easily spot this unnatural, high-volume traffic and simply block those IPs, cutting off your tool's access entirely.
- CAPTCHAs: We've all seen them. Those "I'm not a robot" puzzles are designed to stop automated scripts dead in their tracks. They present challenges that are simple for humans but incredibly difficult for bots to solve, effectively halting the scraping process.
- Dynamic HTML: Modern websites are constantly changing their underlying code and structure. A scraper programmed to find a piece of data in one specific spot will break the moment that structure is updated, rendering it useless until a developer can fix it.
These technical hurdles are a huge reason why so many sales pros struggle with inconsistent results from their tools. For a deeper dive, you might be interested in our guide on what to do when your web scraper is not working.
How ProfileSpider Overcomes This Challenge
So, how do you get reliable data without constantly fighting these digital defenses? The answer is to completely change your approach. Instead of sending loud, obvious bots from a remote server, the smarter method is to operate quietly from within your own authenticated browser session.
The most effective way to avoid detection is to blend in. When a tool’s activity is indistinguishable from your own normal browsing, it becomes dramatically harder for websites to identify and block it.
This is exactly the advantage you get with a tool like ProfileSpider. Because it's a Chrome extension, it doesn’t operate from some suspicious data center IP address. It works locally on your machine, piggybacking on the trust you’ve already established by being logged into a platform.
This no-code approach is a far more subtle and effective way to gather leads:
- It Mimics Human Behavior: Since ProfileSpider runs inside your active browser, its requests look just like yours. There are no high-volume server calls to raise red flags.
- It Bypasses Common Blocks: You're already authenticated and browsing normally. This means the tool sidesteps many of the IP-based blocks and CAPTCHA triggers that plague cloud-based services.
- It Adapts to Page Changes: The AI is designed to understand the semantic structure of a profile, not just a rigid code path. This makes it far more resilient to the minor HTML changes that break less intelligent scrapers.
By operating in this stealthier manner, ProfileSpider dramatically reduces your risk of detection and ensures far more consistent, reliable data. It lets you build your lead lists from social networks, company directories, and industry forums without the constant fear of being blocked.
A Better Playbook for Building Lead Lists
If you’ve been in the sales or recruiting game for a while, you know the old playbook for lead scraping is broken. The endless grind of pulling massive, low-quality lists just doesn’t cut it anymore. It's a high-risk, low-reward cycle that leaves you chasing ghosts, fighting with flaky tools, and walking on eggshells around compliance.
It's time for a smarter framework. Let's ditch that old approach and build a valuable, proprietary lead database that actually fuels growth. This new playbook rests on three core pillars.
Pillar 1: Quality Over Quantity
First thing's first: we need a massive mindset shift. It's all about prioritizing the quality of your leads over the sheer volume. Think about it—a curated list of 50 highly accurate, well-enriched contacts is infinitely more valuable than a junk drawer list of 5,000 outdated profiles.
Quality starts right at the source. Modern tools like ProfileSpider are built on this idea, using AI to extract information directly from your browser. This "local-first" method means you’re grabbing real-time data from a live web page, not some stale, cached version sitting on a server miles away. This simple change dramatically cuts down on the data decay that makes cloud-based scrapers so unreliable.
Pillar 2: Privacy by Design
The second pillar is about building your entire process with privacy as a foundation, not an afterthought. In today's world of tight data protection laws, how you collect and store information is just as important as what you collect. To build truly effective lead lists, it's crucial to understand where your best leads originate and implement effective lead source tracking that respects user privacy.
This is where the architecture of your tools really matters. Most cloud-based scrapers pool everyone's data on central servers, creating a huge compliance headache. ProfileSpider, in contrast, runs on a privacy-by-design model.
All the data you extract is stored locally in your browser's secure storage. It never touches a central server, which means you—and only you—are in control of the information. This design puts you in the driver's seat, aligning your work with modern data privacy standards from the get-go.
This local-first approach sidesteps the risks of third-party data handling, giving you a much more secure and defensible way to manage sensitive contact info.
Pillar 3: Seamless Workflow Integration
Finally, your tools need to slide right into your existing workflow without causing a bunch of friction. A good lead generation system shouldn't feel like a series of clunky, disconnected steps. The goal is to get from identifying a great prospect to reaching out to them as smoothly as possible.
A powerful tool should almost act like a mini-CRM before you even move the data over. ProfileSpider is built for exactly this, letting you:
- Organize on the fly: Use tags and notes to segment leads into custom lists for different campaigns or roles, right as you find them.
- Enrich in one click: Instantly find missing contact details without having to jump between five different tabs and spreadsheets.
- Export cleanly: Generate organized CSV, Excel, or JSON files that are ready to be dropped straight into your main CRM or ATS.
By building your strategy around these three pillars—quality, privacy, and integration—you can finally move past the hidden dangers of outdated scraping. It's a smarter way to build your sales and recruiting pipelines with effectiveness, safety, and a whole lot more confidence.